





IReST's Latest Greek Addition
IReST’s Latest Greek Addition
Expanding Global Sourcing Tracks for Multi-Language Reading Performance Studies
The International Reading Speed Texts (IReST) system introduces its highly anticipated Greek language edition. This release serves as a valuable tool for everyday clinical practice, low-vision patient rehabilitation tracking, and academic research.
By providing identical standardized paragraph difficulties across alternative translations, it functions as an exceptionally powerful medium for cross-language comparison metrics during complex, international multi-center clinical studies.
See Greek Product Details
Standardized multi-line Greek test cards bound for rapid near-vision execution
Assessing Variability in Reading Performance with the New Greek Standardized Reading Speed Texts (IReST)
Gleni A, Ktistakis E, Tsilimbaris MK, Simos P, Trauzettel-Klosinski S, Plainis S. Optom Vis Sci. 2019;96(10):762–770.
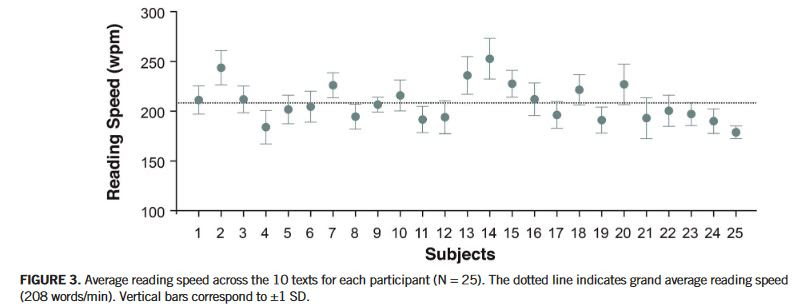
This publication evaluates the standardized Greek translation of the International Reading Speed Texts (IReST) platform. The integration of this layout directly enriches interlanguage comparison parameters and balances variance coefficients across international clinical research trials.
Furthermore, the study rigorously investigates how specific textual characteristics (such as word lengths and sentence structures) and subject-related features (including accommodation capabilities or cognitive age) modulate the core baseline variability of reading speed metrics across continuous paragraphs.

22 Different Languages Available!
Precision Vision, Inc. remains the master manufacturer for an extensive array of reading speed and visual reading acuity charts, including the verified Radner, MNRead, IReST, and Colenbrander Charts.
These configurations compose an international library of 22 distinct languages and dialects, covering: English, Spanish, Hispanic, Brazilian/Portuguese, German, Greek, Dutch, Danish, Finnish, Swedish, Italian, French, Arabic, Chinese, Russian, Hebrew, Polish, Japanese, Slovenian, Turkish, Norwegian, and Tagalog—all calibrated strictly to lock down data repeatability.

Q: What is the process for translating & validating the language charts?
A: All language paragraph and sentence optotypes are engineered explicitly from the ground up according to the foundational psychophysical concept of each chart. Instead of using raw machine translations, each distinct language edition is structured in direct collaboration with a lead university research department alongside an expert panel of linguists, cognitive psychologists, statisticians, and vision physicists to ensure standardized legibility difficulty across targets.


%20system%20introduces%20its%20...){kind=link}